
Le matériel ML peut-il vraiment détecter les ransomwares ? Le pipeline colonial dit oui
Le centre de recherche et l’industrie unissent leurs forces pour se défendre contre les ransomwares à la périphérie intelligente avec du matériel personnalisé et l’apprentissage automatique.
La récente attaque de ransomware sur Colonial Pipeline est un autre rappel douloureux de notre vulnérabilité face à de telles attaques et de la difficulté de défendre nos infrastructures contre elles. Le RaaS (Ransomware as a service) est une industrie florissante dans de nombreux coins sombres du monde, et il est particulièrement difficile de s’en protéger à la périphérie intelligente. Les défis incluent la détection du jour zéro sans exemple précédent ni signature connue, un temps de réponse à faible latence et un débit de détection élevé nécessaire pour gérer les transactions en ligne sans cesse croissantes à la périphérie intelligente. Les défis supplémentaires comprenaient des ressources de calcul et d’alimentation limitées et une architecture matérielle suffisamment flexible pour changer lorsque les conditions de menace changent.
Les chercheurs du Center for Advanced Electronics through Machine Learning (CAEML) ont étudié des solutions matérielles d’apprentissage automatique qui peuvent accélérer la détection des ransomwares à la périphérie intelligente. Le directeur du site du centre et chercheur principal Paul Franzon et son étudiant diplômé Archit Gajjar à NC State s’associent aux ingénieurs de la division de stockage primaire de Hewlett Packard Enterprise pour rechercher la solution matérielle optimale pour détecter les ransomwares à la périphérie.
Il existe des références à l’utilisation de techniques d’apprentissage automatique pour détecter les ransomwares, beaucoup suggérant d’utiliser des classificateurs d’ensembles comme moteur de détection sous-jacent. Nous nous concentrerons sur la recherche de solutions matérielles pouvant accélérer les classificateurs d’ensembles.
Pour évaluer le matériel optimal pour les classificateurs d’ensemble à la périphérie, nous devons considérer les références de performances suivantes. La précision de détection est avant tout. Le classificateur XGBoost est très efficace pour de telles tâches de détection. Il nécessite moins d’arbres et le surajustement peut facilement être contrôlé en limitant la profondeur des arbres. Une approche arborescente peu profonde aide également à l’accélération matérielle et au parallélisme.
Le classificateur doit gérer un nombre ciblé de transactions par seconde ou d’opérations d’entrée/sortie par seconde (IOPS). La cible IOPS typique varie considérablement en fonction de la plate-forme de périphérie, mais 100 000 à 1 000 000 IOPS pour les périphériques de périphérie haut de gamme ne sont pas rares. Certains appareils de transaction en ligne ont également des accords de niveau de service (SLA) qui garantissent un temps de réponse de quelques ms. Cela impose également une exigence de latence au classificateur.
Certains dispositifs intelligents sont censés effectuer différentes inférences pour différentes tâches de manière multiplexée dans le temps. Cela signifie que la taille du lot de traitement des données peut être limitée et que les unités d’exécution seront partagées par d’autres modèles d’inférence. Enfin, les périphériques de périphérie peuvent avoir une alimentation électrique limitée. Une puissance par inférence plus faible pour le matériel est également hautement souhaitable.
À l’aide de 12 cœurs lors de l’analyse comparative, nous avons mis en place les benchmarks ci-dessous et évalué les options matérielles suivantes : Un processeur multicœur Intel (2,3 GHz (base), 2,7 GHz (turbo) Processeur Intel Xeon E5-2686 v4) et GPU (Nvidia Tesla T4) . Certains ransomwares bien connus du domaine public et ensemble de données d’applications de sécurité sont utilisés pour mesurer leur vitesse d’inférence avec ces options matérielles. Les résultats sont les suivants:
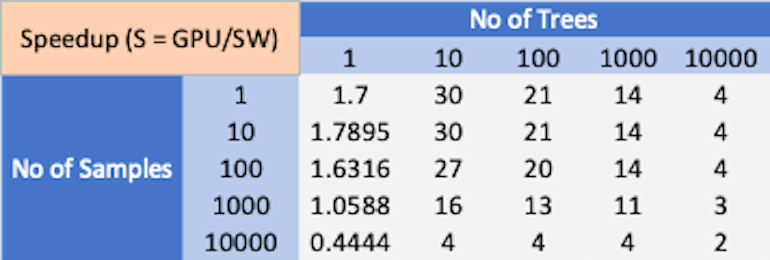
Débit CPU vs GPU avec une latence de 10 ms (WannaCry).
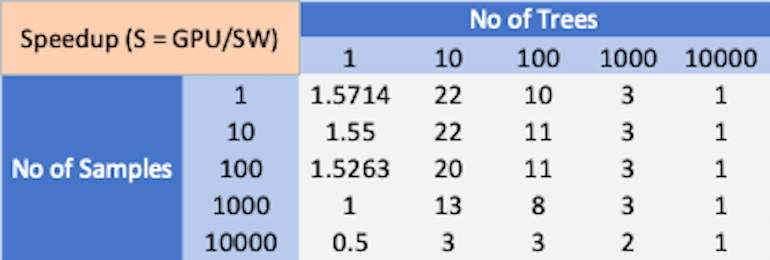
Débit CPU vs GPU avec une latence de 10 ms (CreditCard).
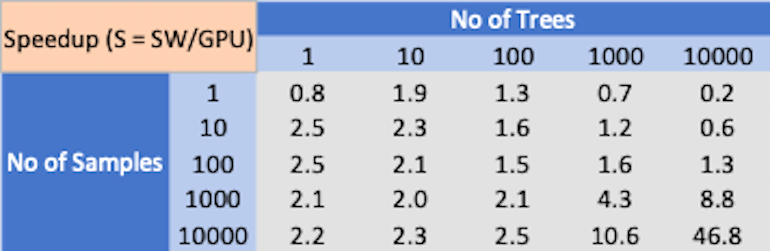
Latence CPU vs GPU (WannaCry).
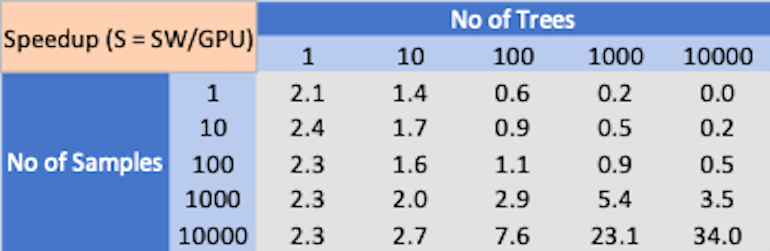
Latence CPU vs GPU (CreditCard).
Comme le montrent les résultats ci-dessus, il n’y a pas de gagnant clair dans les performances d’inférence XGBoost entre le processeur multicœur et le processeur graphique. Selon la complexité du problème et la taille du lot, le CPU ou le GPU peuvent se surpasser.
Il est également bien connu que le processeur typique a un avantage en termes d’efficacité énergétique par rapport au processeur graphique. Certaines références sur les performances d’inférence de forêt aléatoire suggèrent que le GPU subit une perte de performances en raison de problèmes de divergence de branches dans l’exécution des arbres de décision. Cela laisse la porte ouverte au matériel de conception personnalisée qui peut être optimisé pour l’inférence XGBoost. La conception personnalisée peut tirer parti d’une exécution parallèle qui peut surpasser le processeur multicœur tout en évitant les problèmes de divergence de branche comme le GPU.
Les chercheurs du CAEML se sont penchés sur une telle conception et les résultats préliminaires sont très encourageants. Nous nous attendons à un rapport plus détaillé vers la fin de l’année, lorsque le prototype en silicium sera prêt à être testé. Le silicium de conception personnalisée sera également capable de multiplexer d’autres tâches d’inférence XGBoost pour l’inférence de bord.
Alors que de plus en plus d’appareils IoT intelligents sont déployés sur le terrain pour des infrastructures critiques, le besoin de les sécuriser devient primordial. Nous sommes ravis que les chercheurs du CAEML se concentrent sur la conception de cette nouvelle classe de matériel pour aider à garantir l’avantage contre les attaques de ransomware.
Cette recherche est financée en partie par des subventions de la National Science Foundation (prix CNS 16-244770) et des sociétés membres du CAEML.
Inscrivez-vous à DesignCon pour en savoir plus.





